Deepseek蒸馏模型部署的上下文对话管理
又到了白色相簿的季节
之前利用FastAPI部署了网页和API的接口,但是Deepseek蒸馏模型的上下文对话管理一直没有继续完善,刚好最近在实际的使用时看到了一些官方给出的prompt提示,于是打算开始完善一下。划一下重点:
Avoid adding a system prompt; all instructions should be contained within the user prompt.
一开始在vscode里配置Copilot出了点问题,导致我用AI来开发AI的想法难以付诸实施。后来经过一番摸索才发现,在Settings-Application-Proxy里不仅要挂代理,还要把Use Local Proxy Configuration给勾上,于是乎我也用上了Claude Haiku 4.5和GPT5 Mini了。虽然这两个生成代码很厉害,但是让它们给Deepseek蒸馏模型添加上下文对话管理还是会出错,果然人工智能最强的还是人工orz。。。但是它们也给出了一些比较好的思路来帮我完成这个任务:
- 将对话按照OpenAI的chat/completion的格式进行组织
- 根据Max Token数对历史对话进行截断(truncate)
接下来就是具体的实施了,因为实际的部署涉及到API的接口,所以我想将具体的对话拼接放到前端。查阅到官方文档可以看到:
DeepSeek /chat/completions API 是一个“无状态” API,即服务端不记录用户请求的上下文用户在每次请求时,需将之前所有对话历史拼接好后,传递给对话 API。
在实际的使用中,后端的FastAPI实现无需更改,只要在发送请求时按照类似于下面的格式维护好对话列表即可:
[
{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What is the second?"}
]
可以用下面的python脚本进行测试:
import requests
import json
url = "http://your.url/generate"
messages = [{"role": "user", "content": "What's the highest mountain in the world?"},
{"role": "assistant", "content": "The highest mountain in the world is Mount Everest."},
{"role": "user", "content": "What's the second?"}]
# JSON 数据
json_data = {
"prompt": f'{messages}',
"temperature": 0.6,
"max_length": 512
}
# 自定义请求头
headers = {
"Content-Type": "application/json",
"X-API-Key": "填写key"
}
# 发送 POST 请求
response = requests.post(url, json=json_data, headers=headers)
# 打印响应状态码和内容
print("Status Code:", response.status_code)
print("Response Content:", response.text)
print(f"JSON content: {response.json()}")
也就是说每次只需要将自己组织好的对话列表按照上面的格式发送到服务器即可。但是因为显卡的显存有限制,导致了对话列表的上下文不能无限,所以需要根据现存大小对对话历史进行截断。受到一阶马尔科夫链的启发,当前轮对话与上一轮对话相关程度较高,所以我只保存上一轮对话和当前prompt。具体网页js代码如下:
while (msglist.length > 3){
msglist.shift();
}
const prompt = encodeURIComponent(JSON.stringify(msglist));
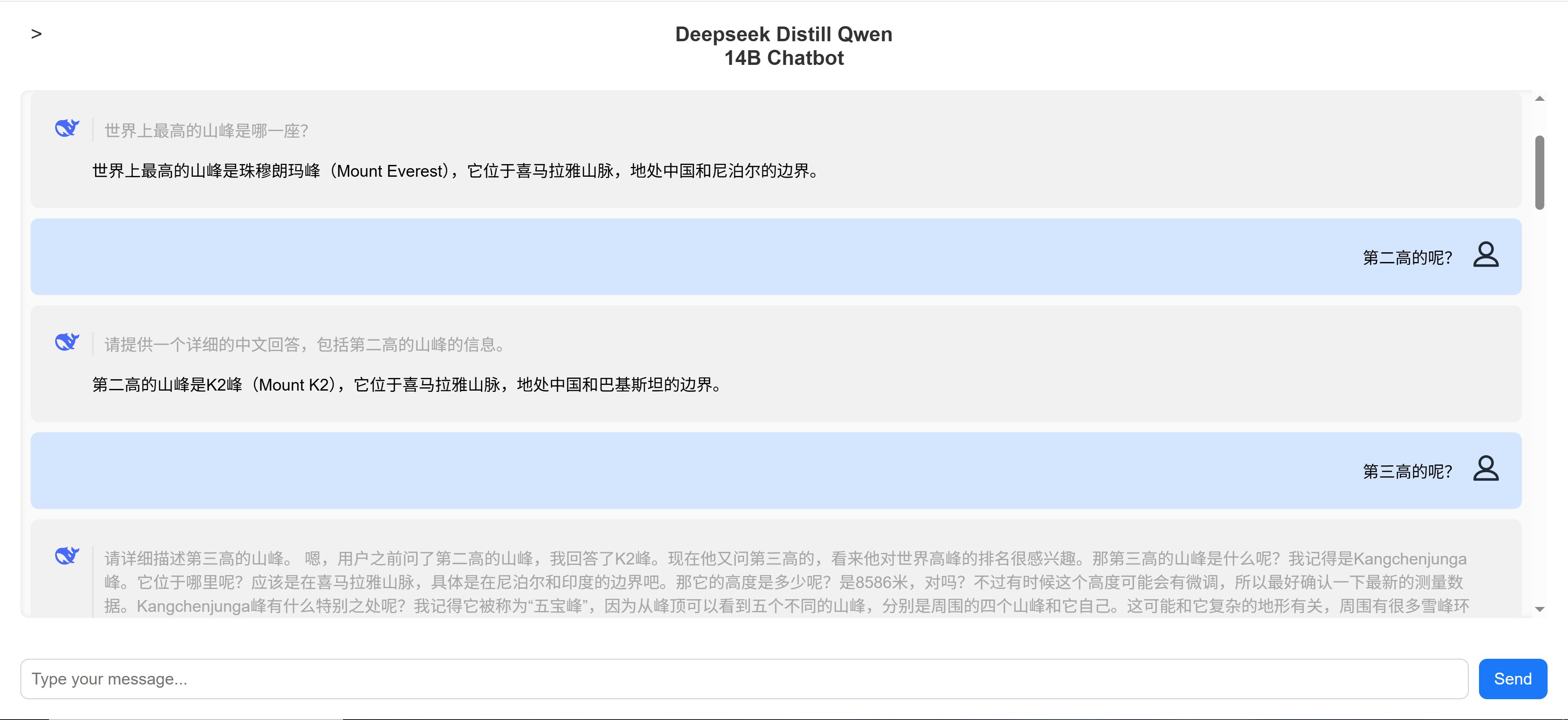
后面对话效果也确实验证了我的猜想。
| 微信(WeChat Pay) | 支付宝(AliPay) |

|

|
| 比特币(Bitcoin) | 以太坊(Ethereum) |

|

|
| 以太坊(Base) | 索拉纳(Solana) |

|

|